Selfie2Anime.com has been growing much faster than we ever anticipated! That’s awesome and it has been an incredible journey thus far! The high demand on the site has created some interesting scalability challenges that we have managed to overcome without too many hiccups (although there definitely were some). Here’s some insight on how we did it.
We started this project with relatively humble expectations, trying to just get out an MVP as soon as possible and see where it goes. Well, it definitely went somewhere. At the time of writing this blog post, users of Selfie2Anime.com have uploaded over 264,675 selfies that have subsequently been processed by the system and sent back to them by e-mail.
From Russia with Love
If we take a look at our (rough) real-time location statistics from Google Analytics right now, we can identify a certain demography that seems to be quite fond of the service:
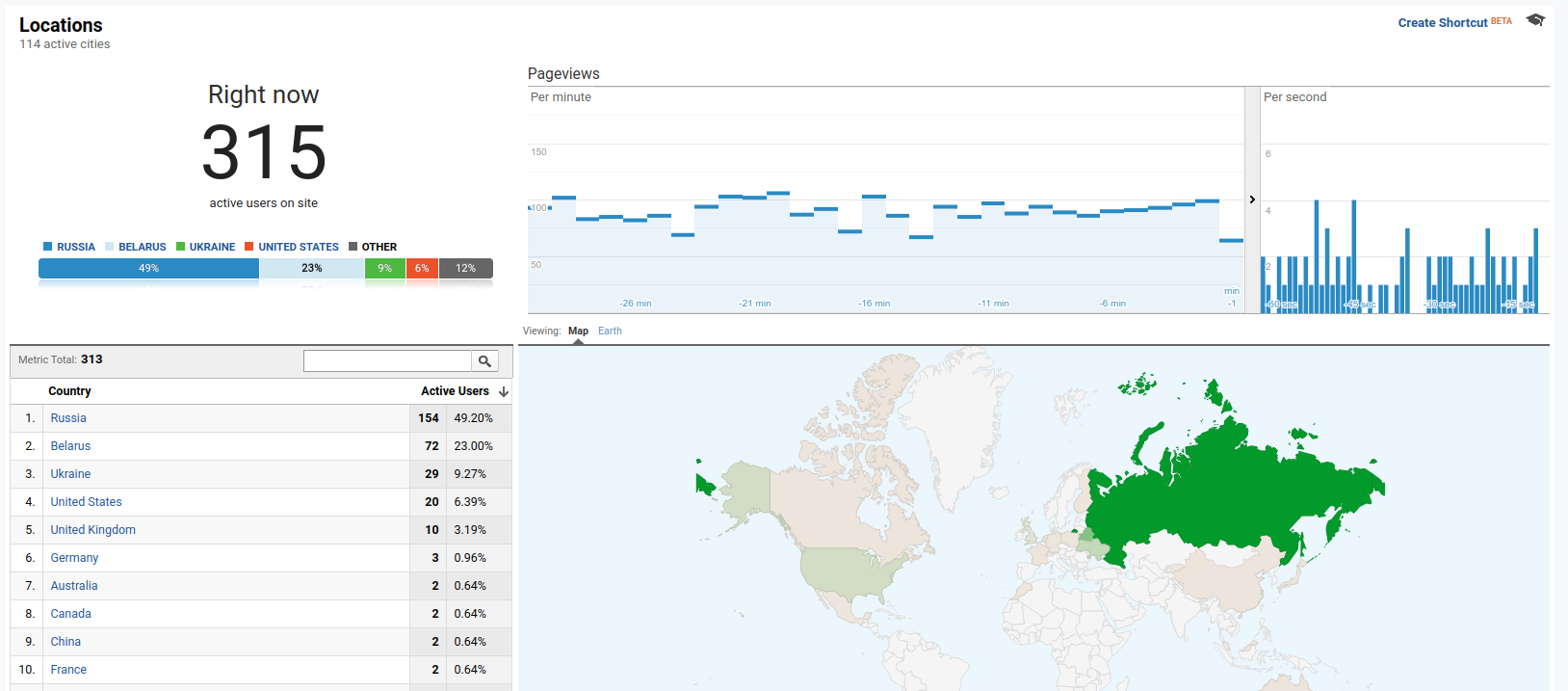
Since launch, the majority of our users are from Russia (Приве́т!  ), followed by other users from Eastern Europe (Ukraine and Belarus), totalling over 70% of our traffic. Here’s a Top 10 list of countries that are using our service the most:
), followed by other users from Eastern Europe (Ukraine and Belarus), totalling over 70% of our traffic. Here’s a Top 10 list of countries that are using our service the most:
- Russia (61.23%)
- United States (11.17%)
- Ukraine (6.80%)
- Belarus (2.74%)
- United Kingdom (1.94%)
- Kazakhstan (1.54%)
- Canada (1.11%)
- Germany (0.93%)
- Poland (0.75%)
- Taiwan (0.70%)
We have no clue why Selfie2Anime.com is so popular in Russia, but it seems to be the only country where the word is being spread through several different news articles and on the social network VK.  If any of our Russian friends read this, please post your explanation down below in the comments!
If any of our Russian friends read this, please post your explanation down below in the comments!
Ramping Up Scalability
After we have started to receive a sudden influx of new users, we had to focus our attention on optimizing both the front-end and the back-end to reduce network traffic and number of requests, limiting storage, and optimizing the processing of selfies through the GAN.
Optimizing the Website
Most of the optimizations (and thus cost reduction) have been achieved by tweaking the website itself. This is a list of optimizations I have performed on the front-end in descending order of effectiveness:
Lazy-Loading Portfolio Images
If you scroll down to the portfolio section, you’ll see a wall-of-pictures showing a number of anime-selfies that have been generated. If you hover on the individual images with your mouse cursor (or touch them with your finger), the original selfie will be revealed. Unfortunately, we are talking about 96 × 2 = 192 different pictures, each fetched through a separate web request. While this approach has been good enough for the MVP, it was now time to optimize.
First, I implemented lazy-loading for the images so that the web browser would only fetch images from the server if the user actually scrolled down. As most users are mainly interested in getting their selfies, this approach proved to be immensely effective. To make the loading process more visually pleasing, a ‘placeholder color’ is shown while the images are being downloaded.
Secondly, I looked into sprite sheets/image atlases, with which all images are stored in a single large image file and are then split up into separate smaller images on the client. Unfortunately, I did not find a good, cross-device compatible way to achieve this (let me know if you have an idea).
Optimizing Images and Content Files
The second step was to more aggressively optimize images and content files. HTML, CSS, and JavaScript files were already being compressed (‘uglified’) by Webpack. However, some of the dependencies, namely Bootstrap, external libraries, and font files, could be moved away from our servers completely and be hosted externally on publicly available Content Distribution Networks.
For the optimization of image files, I have set up a custom build script that takes care of generating portfolio images (and previews), and automatically compresses images automatically using Guetzli. Guetzli is a powerful JPEG encoder developed by Google, that tries to reduce file size without reducing the perceived image quality. It works incredibly well, but it is also extremely slow. Absolutely worth the hassle, though.
Hashing & Caching
The third step in our effort to optimize the front-end was to introduce content hashing and set up proper caching. When the content of the site is being generated, the build process calculates the hashes of individual files and uses them as part of the filename, e.g. app.52feb7db.js. This has the benefit that the files can be cached indefinitely because the filename changes with the content.
Optimizing the Backend
In Nathan’s post, he has shown the initial configuration of the system:
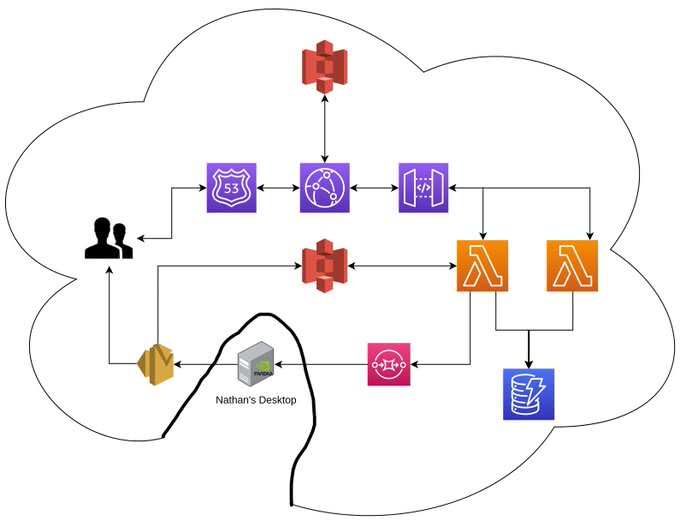
The part that really sticks out is that, initially, the computation-intensive processing of the selfies has been performed on Nathan’s computer, making it a part of ‘the cloud’ that has been serving thousands of users. Personally, I think this is just hilarious.  Unfortunately, of course, it did not take long for his computer to become the bottleneck.
Unfortunately, of course, it did not take long for his computer to become the bottleneck.
I made some optimizations in the code to streamline the process and give us some more throughput temporarily, but demand kept rising rapidly. At this point, Nathan started migrating the processing away from his computer onto Google Cloud Computing Services. He did an excellent job at making the system fully scalable using multiple on-demand computation nodes, processing the selfie-queue in parallel.
Results
Nathan and I are happy about the results we achieved after having performed the optimizations discussed earlier (and a few smaller ones en-passent):
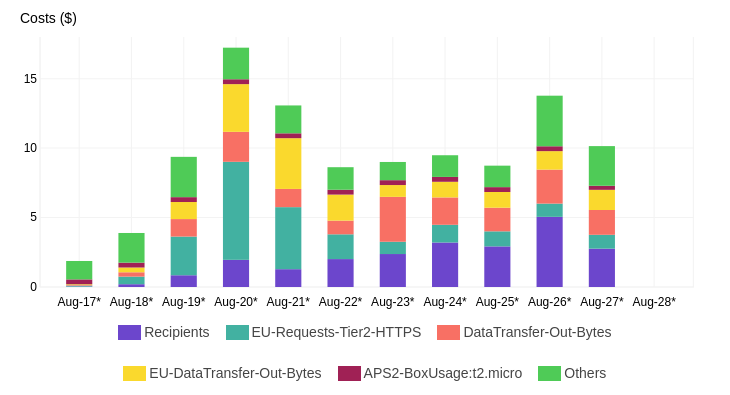
We deployed the changes during August 21. The reduction in cloud and computation costs was considerable, especially given the fact that demand has since been rising dramatically.
There haven’t been any major hiccups and things have been running rather smoothly. Our queues stalled last night for a short while because we have hit AWS SES limits. However, all pending requests have been fulfilled once the limits were increased by Amazon. Other than that, so far, smooth sailing.